书生浦语模型类型
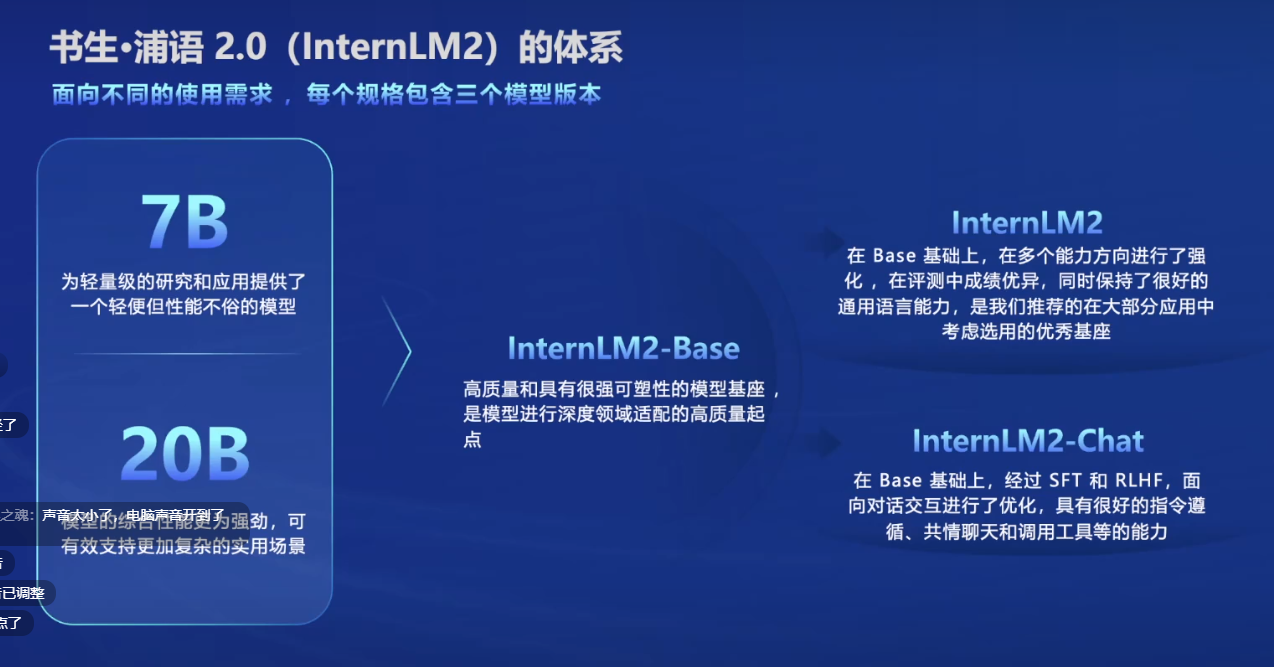
规模:7B、20B
InternLM2_Base :高质量、强可塑性的基座模型
InternLM2 :在Base基础上,在多个能力进行了强化,更优秀的基座模型
Chat-SFT :在Base基础上,经过有监督微调SFT后的对话模型
InternLM2-Chat :在Chat-SFT基础上,再经过RLHF对齐后的对话模型
InternLM亮点
- 超长上下文,200k token
- 在数学、代码能力上比肩ChatGPT
- 具有代码解释器

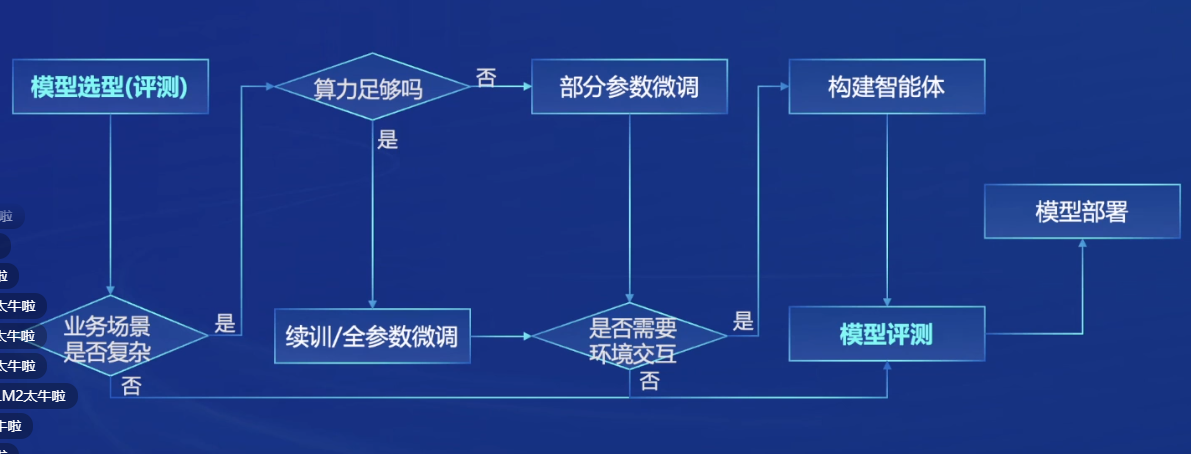
模型到应用
根据业务场景 评估所需要的算力
来决定到底采用续训练/全参数微调,还是部分参数微调
如果需要和环境进行交互,那么则需要构建AI agent
开源链条
下面结合InternLM2 技术报告 arxiv.org/pdf/2403.17297.pdf
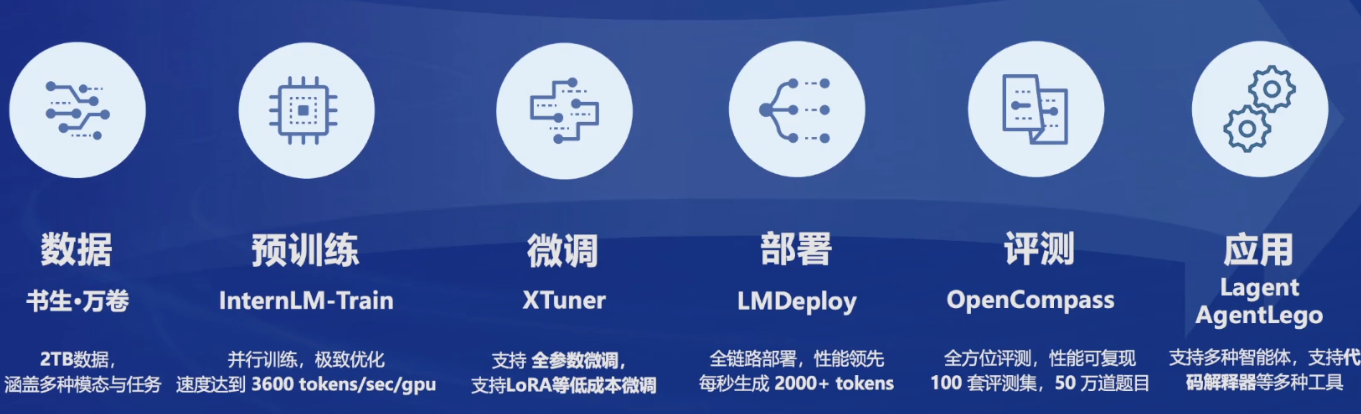
数据集
书生万卷1.0 2TB
书生万卷CC 400GB
开源数据集平台OpenDataLab:OpenDataLab
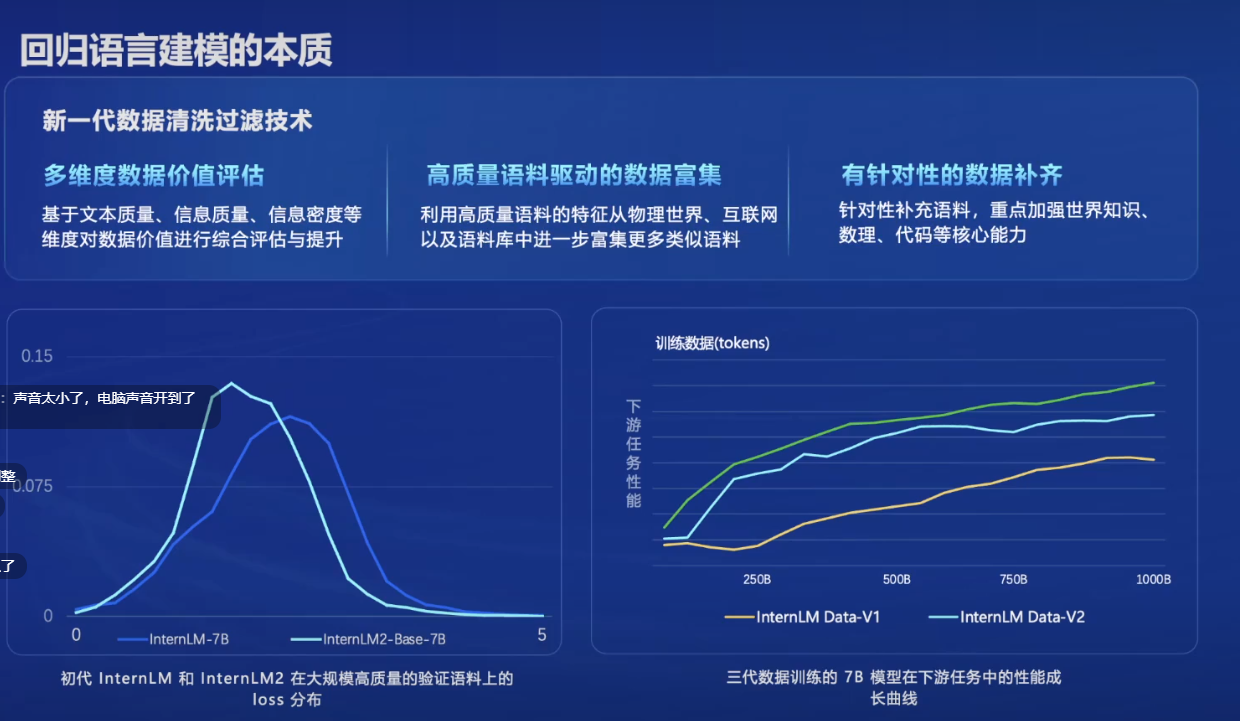

数据处理
预训练数据包括文本数据、代码数据、超长上下文数据
文本数据预处理流程 :jsonl格式化 –> 去重 –> 去乱码 –> 去有害 –> 去广告 –> 去低质
代码数据预处理流程 :md格式化 –> 去重 –> 去低质 –> 依赖排序
超长上下文数据预处理 :长文本选择 –> 统计过滤 –> 上下文关联性过滤
预训练
internEvo: 预训练框架,可以pretrain,SFT,RLHF
支持多种并行训练方式:data,tensor,squence,pipeline
同时使用了2019的 Zero Redundancy Optimizer 用于减少训练显存开销,此外还有2023 FlashAttention,2023 mixed-precision training 增加硬件的利用率。
这3篇文章论文的效率提升,正是我目前所需要的。
微调 Xtuner 适配20系列以上的显卡,只需要8GB显存即可微调7B模型

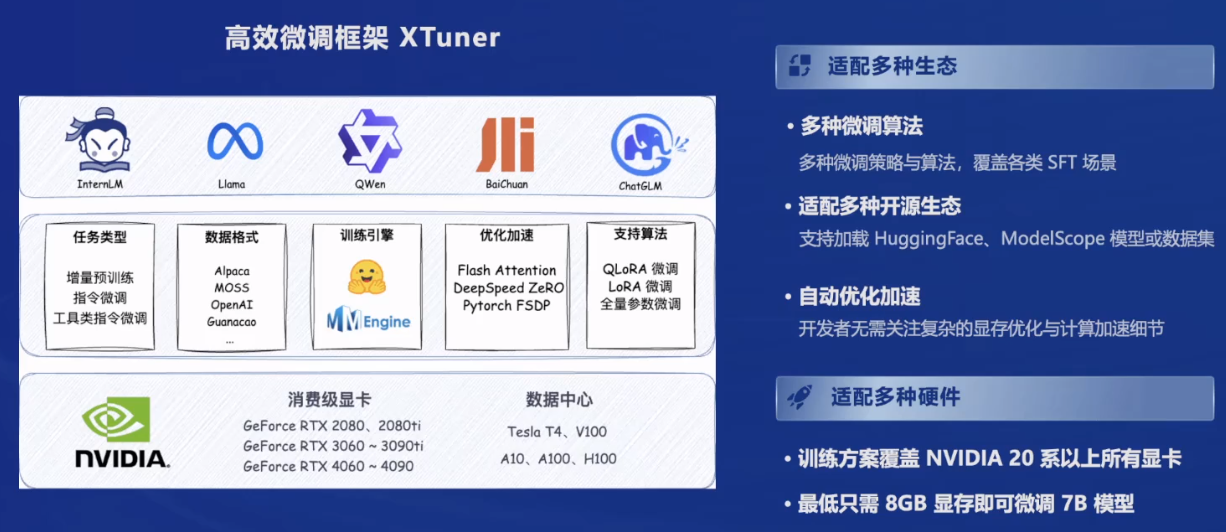
在训练阶段,7B和20B模型分别使用AdamW优化器,初始学习率为4e-5,进行了一个epoch的训练。
在训练步骤中每个微批的每次向前和向后传递期间,InternEvo通过AllGather有效地预取即将到来的层的完整参数集,同时并发地计算当前层。生成的梯度通过ReduceScatter在参数分片组内进行同步,随后使用AllReduce在参数分片组之间进行同步。 这里将分布式通信的过程与训练的过程重叠在一起,最大限度地提高了训练管道的效率。
模型架构
总体遵循LLaMA的结构设计原则,沿用了RMSNorm和SwiGLU激活函数,除此之外
- 对模型中的权重矩阵如Wk, Wq, Wv进行了调整,以支持不同的张量并行转换,并提高训练速度。
- 为了支持长上下文,采用了分组查询注意力 (GQA)结构,以便在处理非常长的上下文时保持高速和低GPU显存消耗。
评测
openCompass2.0
CompassKit 大模型评测全站工具链,可以用于查看大模型能力榜单
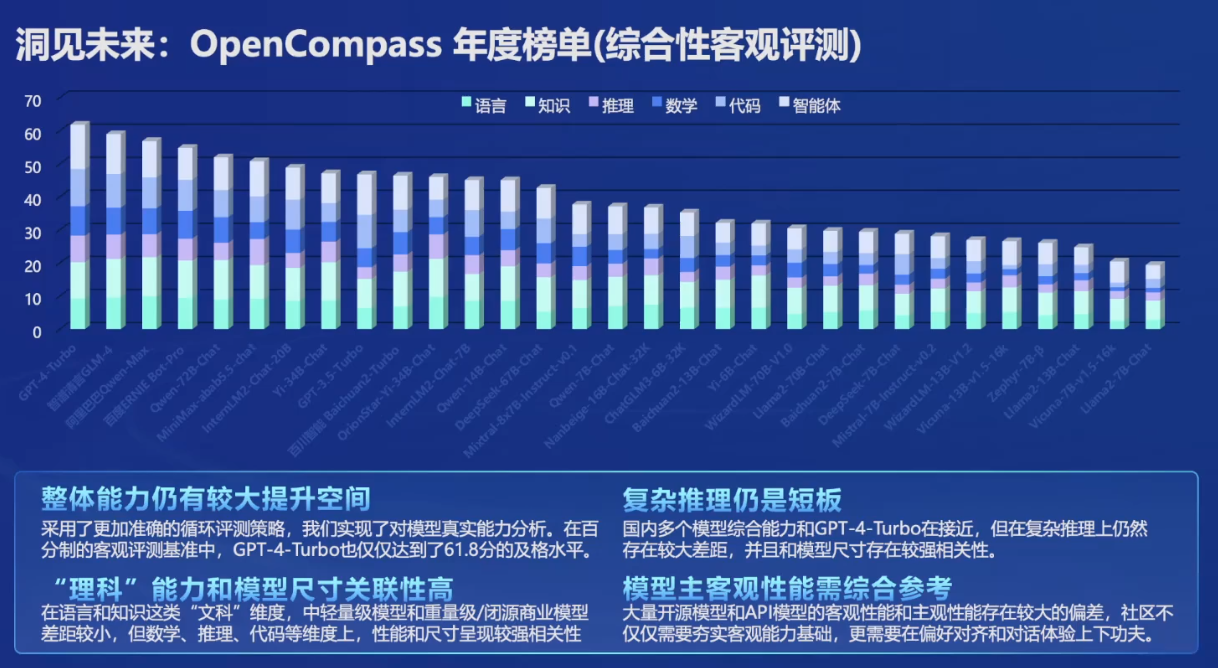
CompassHub 高质量基准数据集,其中评测最高分为gpt4turbo,61.8分。应该算标准比较高的。
部署
LMDeploy
欢迎来到 LMDeploy 的中文教程! — lmdeploy 0.2.6 文档
它提供大模型在GPU上部署的全流程解决方案,包括模型轻量化、推理和服务。
轻量化:支持4bit权重,8bitK/V cache
推理引擎:turbomind、pytorch
服务:openai-sever、gradio、trition inference server
和deepmind有一定差距

轻量级智能体框架
- agents 实现了多种智能体,如 ReAct,AutoGPT。
- llms 支持多种大语言模型,包括在 HuggingFace 上托管的开源模型(Llama-2, InterLM)及 GPT3.5/4 等闭源模型。
- actions 包含一系列工具,并提供工具执行器来统一管理。
目前看起来还是比较简略的。
远远比不上autogen